¿Por qué solo se rastrean algunas de las páginas de mi sitio web?
Si has observado que solo se rastrean de 4 a 6 páginas de tu sitio web (tu página de inicio, las URL de los sitemaps y robots.txt), lo más probable es que se deba a que nuestro bot no ha podido encontrar enlaces internos salientes en tu página de inicio. A continuación encontrarás las posibles causas de este problema.
Puede que no haya enlaces internos salientes en tu página principal, o que estén incluidos en JavaScript. Nuestro bot analiza el contenido JavaScript solo con los niveles de suscripción Guru y Business del kit de herramientas de SEO. Por lo tanto, si no tienes el nivel Guru o Business y tu página de inicio contiene enlaces a otras partes de tu sitio dentro de elementos JavaScript, no detectaremos ni rastrearemos esas páginas.
Si bien el rastreo de JavaScript solo está disponible con los niveles Guru y Business, podemos rastrear el HTML de las páginas que contengan elementos JavaScript. Además, nuestros controles de rendimiento pueden revisar los parámetros de tus archivos JavaScript y CSS, independientemente de tu nivel de suscripción.
En ambos casos, hay una forma de garantizar que nuestro bot rastree tus páginas. Para ello, tienes que ir a "Páginas a rastrear" en la configuración de tu campaña y cambiar la fuente de rastreo de "sitio web" a "sitemap" o "URL desde archivo":
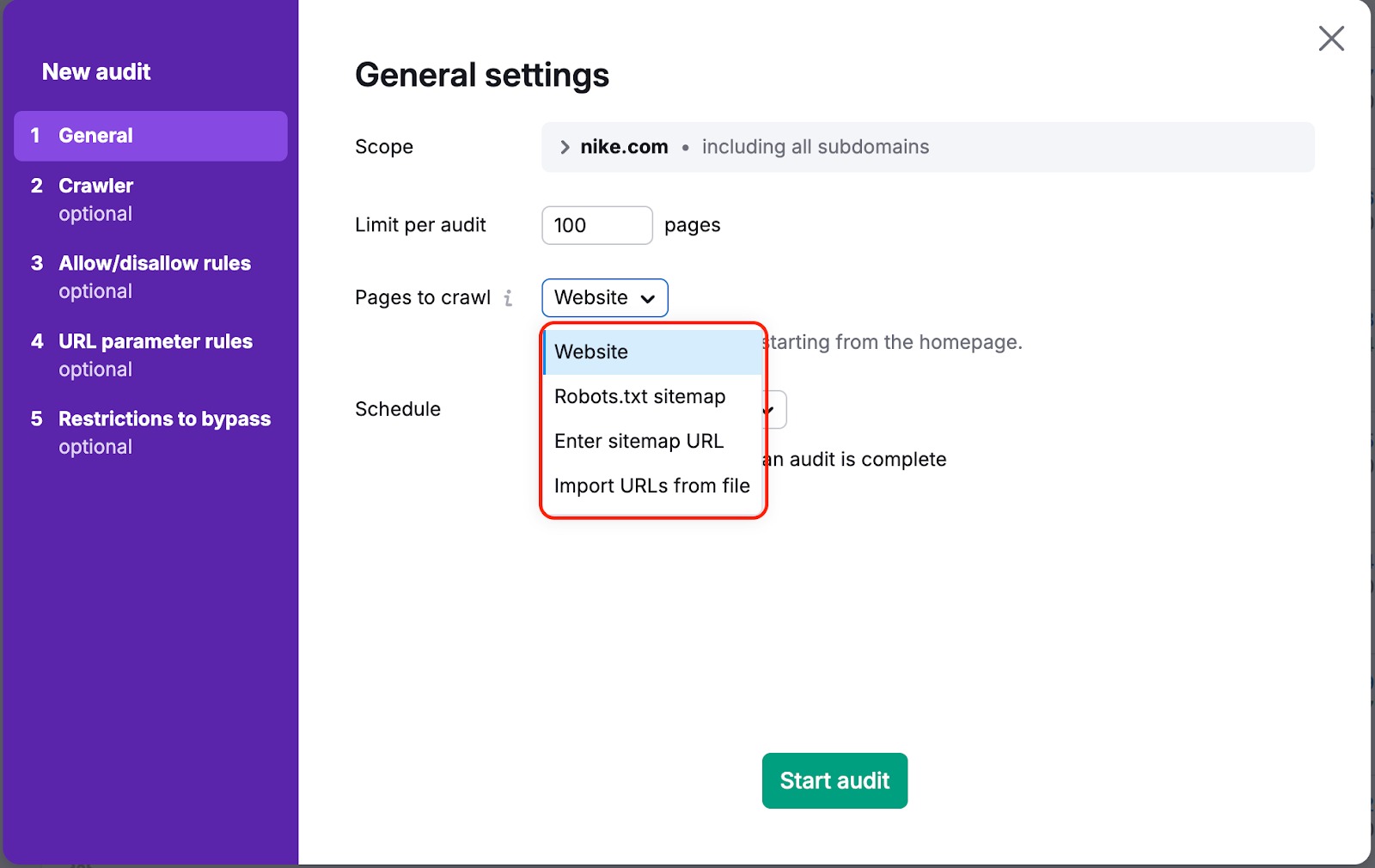
"Sitio web" es la fuente por defecto. Significa que rastreamos tu web usando un algoritmo breadth-first search y navegando a través de los enlaces que encontremos en el código de tu página, comenzando por la página de inicio.
Si eliges una de las otras opciones, rastrearemos los enlaces que se encuentren en el sitemap o en el archivo que subas.
Nuestro rastreador de Auditoría del sitio podría estar bloqueado para algunas páginas en robots.txt o por etiquetas noindex/nofollow. Puedes comprobar si es así en el informe Páginas rastreadas:
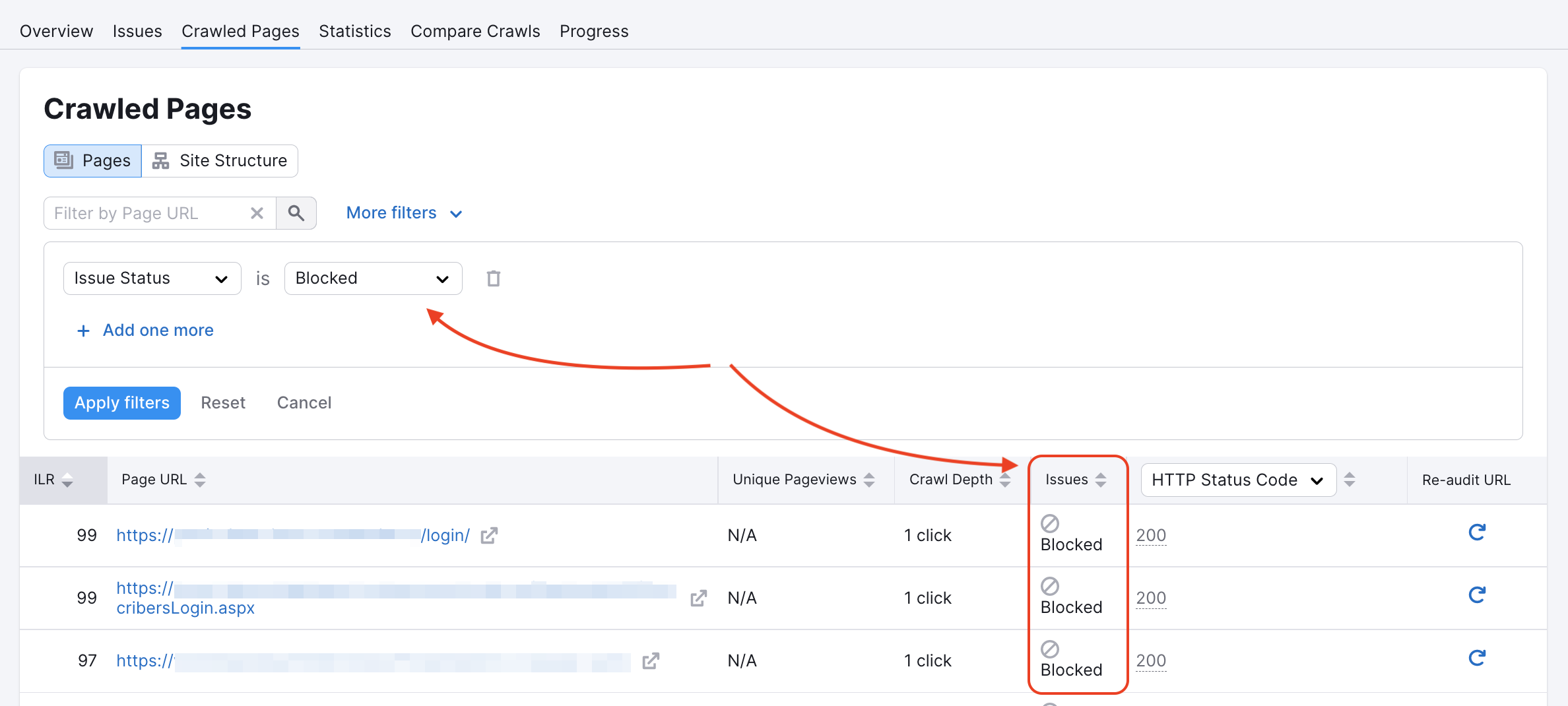
Puedes inspeccionar tu Robots.txt en busca de comandos disallow que impidan a rastreadores como el nuestro acceder a tu sitio web.
Si en la página principal de un sitio web aparece el código que figura más abajo, significa que no está permitido indexar o seguir enlaces ni tampoco acceder al sitio web. Asimismo, el hecho de que en una página aparezca al menos uno de estos dos códigos, "nofollow" o "none", provocará un error de rastreo.
Encontrarás más información sobre estos errores en nuestro artículo sobre solución de problemas.
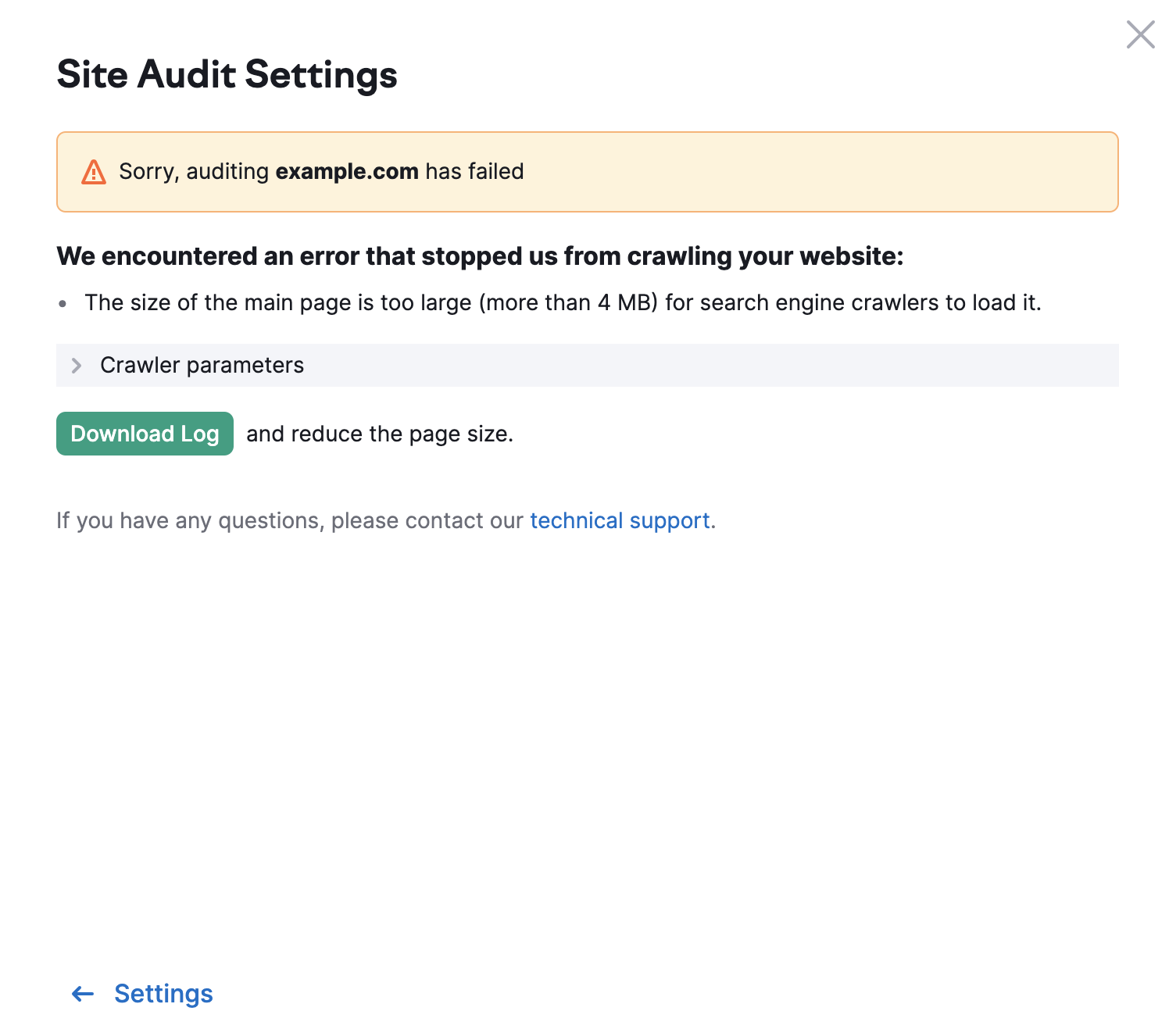
El límite para otras páginas de tu sitio web es de 2 MB. En caso de que una página tenga un tamaño HTML demasiado grande, verás el siguiente error:
