¿Qué es robots.txt?
Robots.txt es un archivo de texto con instrucciones para los robots de los motores de búsqueda que les indica qué páginas pueden y no pueden rastrear.
Estas instrucciones se especifican "permitiendo" o "desautorizando" el comportamiento de ciertos (o todos) los bots.
Este es el aspecto de un archivo robots.txt:
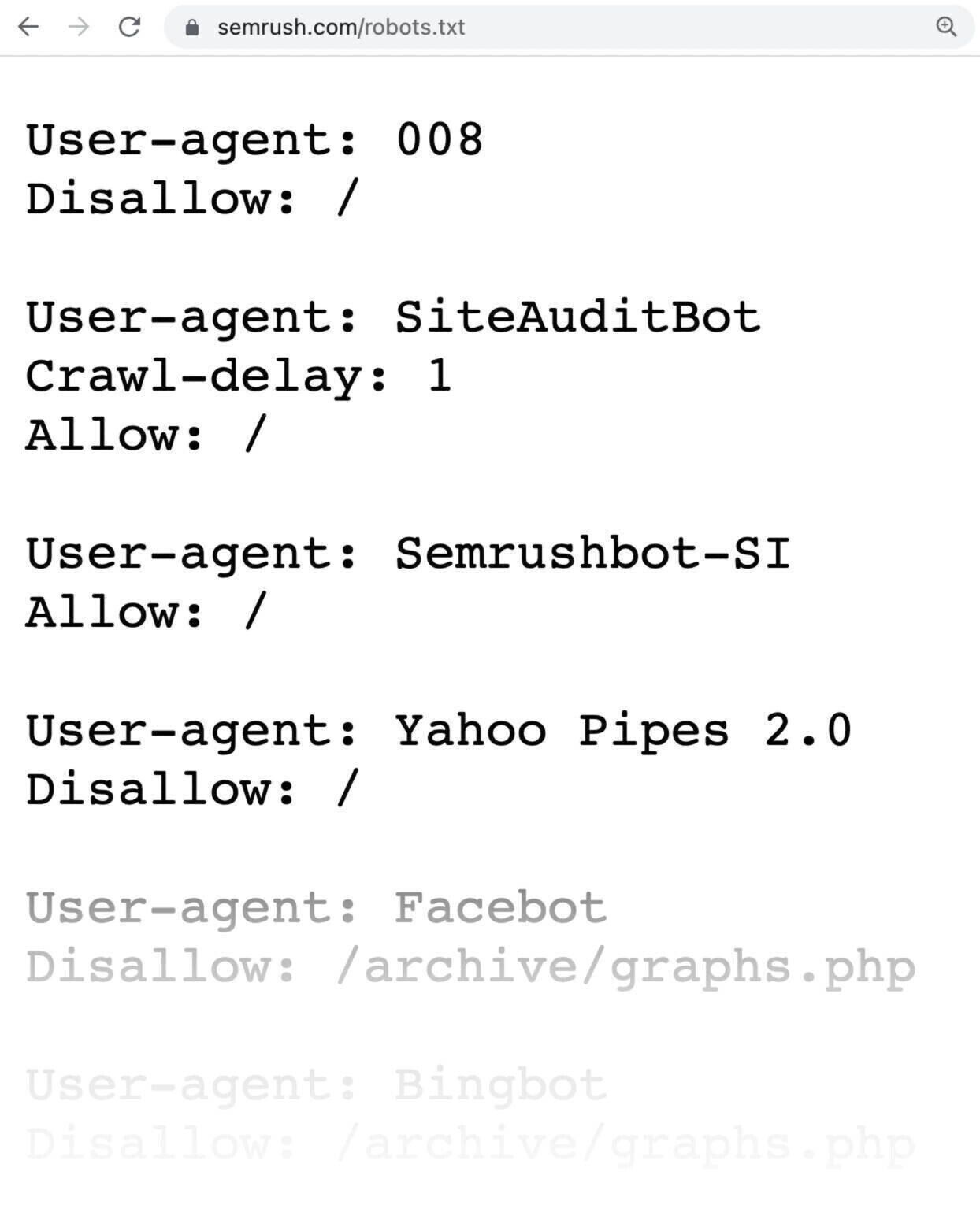
Los archivos robots.txt pueden parecer inicialmente complicados, pero la sintaxis (lenguaje informático) es bastante sencilla. Entraremos en esos detalles más adelante.
En este artículo repasaremos:
- Por qué son importantes los archivos robots.txt
- Cómo funcionan los archivos robots.txt
- Cómo crear un archivo robots.txt
- Mejores prácticas de robots.txt
¿Por qué es importante el archivo robots.txt?
Un archivo robots.txt ayuda a gestionar las actividades de los rastreadores web para que no trabajen en exceso en tu web ni indexen páginas que no están destinadas a ser vistas por el público.
He aquí algunas razones por las que querrías utilizar un archivo robots.txt:
1. Optimizar el presupuesto de rastreo
El "presupuesto de rastreo" es el número de páginas que Google rastreará en tu web. El número puede variar en función del tamaño de tu web, su estado y los backlinks.
El presupuesto de rastreo es importante porque si el número de páginas supera el presupuesto de rastreo, habrá páginas que no se indexarán.
Y las páginas que no se indexan no van a posicionarse.
Al bloquear las páginas innecesarias con robots.txt, Googlebot (el rastreador web de Google) puede dedicar más presupuesto de rastreo a las páginas que sí te importan.
2. Bloquear páginas duplicadas y no públicas
No es necesario que permitas que los motores de búsqueda rastreen todas las páginas de tu web, porque no todas tienen que posicionarse.
Algunos ejemplos son los sitios de pruebas, las páginas de resultados de búsqueda interna, las páginas duplicadas o las páginas de inicio de sesión.
WordPress, por ejemplo, desactiva automáticamente /wp-admin/ para todos los rastreadores.
Estas páginas tienen que existir, pero no necesitas que se indexen y se encuentren en los motores de búsqueda. Es un ejemplo perfecto de cómo utilizarías el archivo robots.txt para bloquear páginas a los rastreadores y bots.
3. Ocultar recursos
A veces querrás que Google excluya de los resultados de la búsqueda recursos como PDF, vídeos e imágenes.
Quizá quieras mantener esos recursos en privado o que Google se centre en contenidos más importantes.
En ese caso, el uso de robots.txt es la mejor manera de evitar que se indexen.
¿Cómo funciona un archivo robots.txt?
Los archivos robots.txt indican a los robots de los motores de búsqueda qué URL pueden rastrear y, sobre todo, cuáles no.
Los motores de búsqueda tienen dos trabajos principales:
- Rastrear la web para descubrir contenidos.
- Indexar el contenido para mostrarlo a los buscadores que buscan información.
Al rastrear, los robots de los motores de búsqueda descubren y siguen enlaces. Este proceso les lleva del sitio A al sitio B y al sitio C a través de miles de millones de enlaces y sitios.
Al llegar a cualquier sitio, lo primero que hará un bot es buscar un archivo robots.txt.
Si encuentra uno, leerá el archivo antes de hacer cualquier otra cosa.
Si recuerdas, un archivo robots.txt tiene el siguiente aspecto:

La sintaxis es muy sencilla.
Asignas reglas a los bots indicando su User-agent (el bot del buscador) seguido de los comandos (las reglas).
También puedes utilizar el comodín del asterisco (*) para asignar comandos a todos los user-agent. Esto significa que la regla se aplica a todos los bots, en lugar de a uno en concreto.
Por ejemplo, así serían las instrucciones si quisieras permitir que todos los bots, excepto DuckDuckGo, rastrearan tu web:

Nota: aunque un archivo robots.txt proporciona instrucciones, no puede hacerlas cumplir. Es como un código de conducta. Los buenos bots (como los de los motores de búsqueda) seguirán las reglas, pero los malos bots (como los de spam) las ignorarán.
Cómo encontrar un archivo robots.txt
El archivo robots.txt está alojado en tu servidor, como cualquier otro archivo de tu web.
Puedes ver el archivo robots.txt de cualquier web escribiendo la URL completa de la página de inicio y añadiendo después /robots.txt, como https://semrush.com/robots.txt.

Nota: un archivo robots.txt debe estar siempre en la raíz de tu dominio. Así, para el sitio www.ejemplo.com, el archivo robots.txt se encuentra en www.ejemplo.com/robots.txt. Si lo colocas en cualquier otro lugar, los rastreadores asumirán que no tienes el archivo.
Antes de aprender a crear un archivo robots.txt, veamos la sintaxis que contienen.
Sintaxis de robots.txt
Un archivo robots.txt se compone de:
- Uno o varios bloques de "comandos" (reglas);
- Cada uno con un "user-agent" específico (bot del motor de búsqueda);
- Y una instrucción de "allow" o "disallow"
Un bloque sencillo puede tener este aspecto:
User-agent: Googlebot
Disallow: /not-for-google
User-agent: DuckDuckBot
Disallow: /not-for-duckduckgo
Sitemap: https://www.tuweb.com/sitemap.xmlEl comando user-agent
La primera línea de cada bloque de comandos es el "user-agent", que identifica al rastreador al que se dirige.
Así, si quieres decirle al Googlebot que no rastree tu página de admin de WordPress, por ejemplo, tu comando empezará así:
User-agent: Googlebot
Disallow: /wp-admin/Ten en cuenta que la mayoría de los motores de búsqueda tienen varios rastreadores. Utilizan diferentes rastreadores para su índice normal, imágenes, vídeos, etc.
Los motores de búsqueda siempre eligen el bloque de comandos más específico que puedan encontrar.
Digamos que tienes tres conjuntos de comandos: uno para *, otro para el Googlebot y otro para Googlebot-Image.
Si el user-agent Googlebot-News rastrea tu web, seguirá los comandos de Googlebot.
Por otro lado, el user-agent Googlebot-Image seguirá los comandos más específicas de Googlebot-Image.
Aquí puedes ver una lista detallada de los rastreadores web y sus diferentes agentes de usuario.
El comando disallow
La segunda línea de cualquier bloque de comandos es la línea "disallow".
Puedes tener varios comandos disallow que especifiquen a qué partes de tu web no puede acceder el rastreador.
Una línea "disallow" vacía significa que no estás deshabilitando nada, por lo que un rastreador puede acceder a todas las secciones de tu web.
Por ejemplo, si quieres permitir que todos los motores de búsqueda rastreen toda tu web, tu archivo tendría el siguiente aspecto:
User-agent: *
Allow: /Por otro lado, si quieres bloquear a todos los motores de búsqueda para que no rastreen tu web, te encontrarías algo parecido a esto:
User-agent: *
Disallow: /Los comandos como "allow" y "disallow" no distinguen entre mayúsculas y minúsculas, así que depende de ti ponerlas en mayúsculas o no.
Sin embargo, los valores dentro de cada comando sí distinguen entre mayúsculas y minúsculas.
Por ejemplo, /foto/ no es lo mismo que /Foto/.
Aun así, a menudo encontrarás los comandos "Allow" y "Disallow" en mayúsculas porque facilita la lectura del archivo a los humanos.
El comando allow
El comando “allow” permite a los motores de búsqueda rastrear un subdirectorio o una página concreta, incluso en un directorio que de otro modo estaría prohibido.
Por ejemplo, si quieres evitar que Googlebot acceda a todas las entradas de tu blog excepto a una, tu comando podría ser así:
User-agent: Googlebot
Disallow: /blog
Allow: /blog/ejemplo-postNota: No todos los motores de búsqueda reconocen este comando. Google y Bing sí lo admiten.
El comando sitemap
El comando "sitemap" indica a los motores de búsqueda, concretamente a Bing, Yandex y Google, dónde encontrar tu sitemap XML.
Los sitemaps generalmente incluyen las páginas que quieres que los motores de búsqueda rastreen e indexen.
Puedes encontrar esta directiva en la parte superior o inferior de un archivo robots.txt, y tiene el siguiente aspecto.
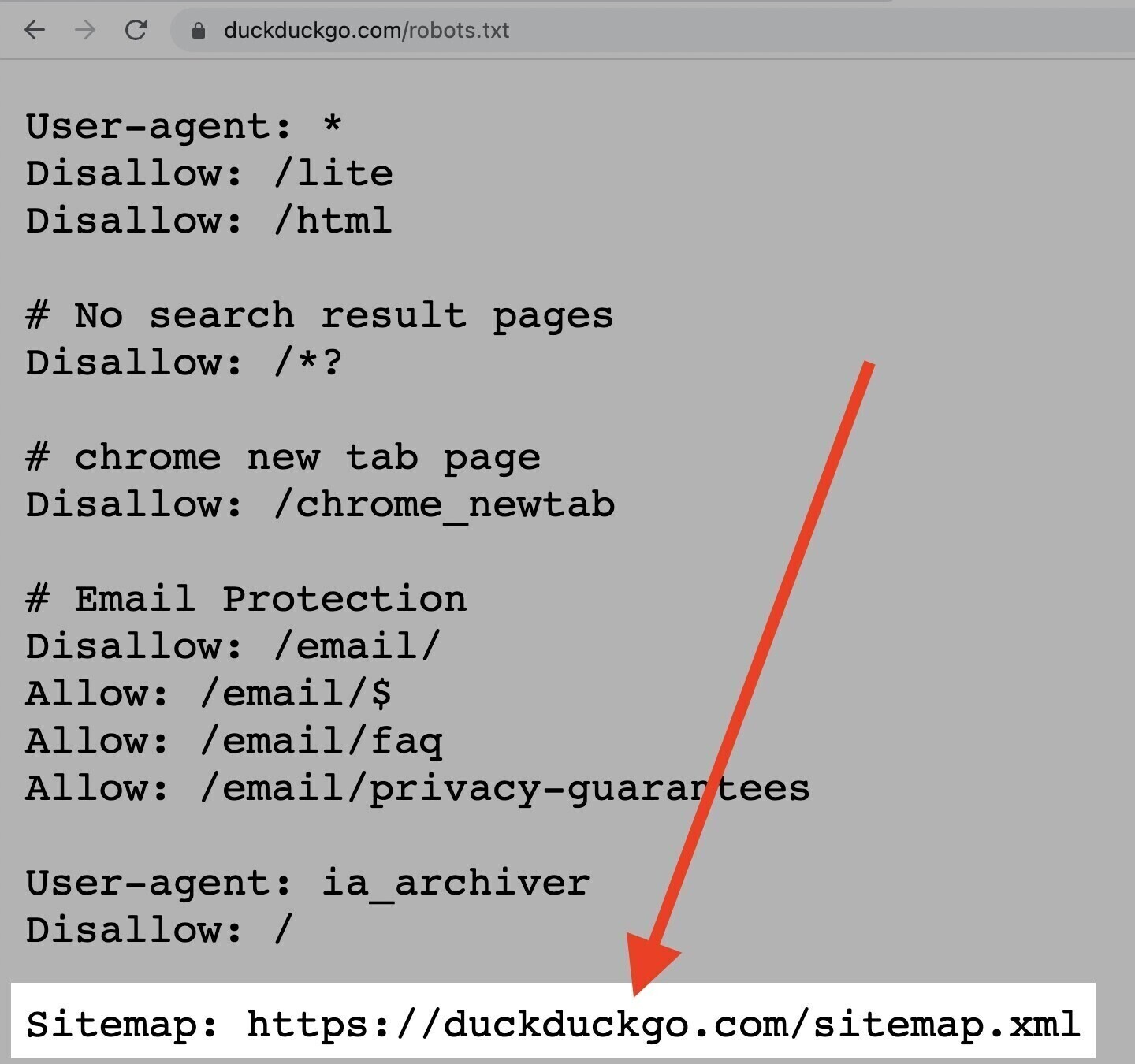
Dicho esto, también puedes (y debes) enviar tu sitemap XML a cada motor de búsqueda utilizando sus herramientas para webmasters.
Los motores de búsqueda acabarán rastreando tu web, pero el envío de un sitemap acelera el proceso de rastreo.
Si no quieres hacerlo, añadir un comando "sitemap" a tu archivo robots.txt es una buena alternativa rápida.
El comando crawl-delay
El comando "crawl-delay" especifica un retraso de rastreo en segundos. Está pensado para evitar que los rastreadores sobrecarguen un servidor (es decir, que ralenticen tu web).
Sin embargo, Google ya no admite este comando.
Si quieres definir tu tasa de rastreo para Googlebot, tendrás que hacerlo en Search Console.
Bing y Yandex, en cambio, sí admiten el comando crawl-delay.
Así es como puedes utilizarlo.
Si quieres que el rastreador espere 10 segundos después de cada acción de rastreo, puedes definir el retardo en 10, así:
User-agent: *
Crawl-delay: 10El comando noindex
El archivo robots.txt le dice a un bot lo que puede o no puede rastrear, pero no puede decirle a un motor de búsqueda qué URL no debe indexar y mostrar en los resultados de búsqueda.
La página seguirá apareciendo en los resultados de la búsqueda, pero el bot no sabrá lo que hay en ella, por lo que tu página tendrá este aspecto:

Google nunca apoyó oficialmente este comando, pero los profesionales SEO pensaron durante mucho tiempo que seguía las instrucciones.
Sin embargo, el 1 de septiembre de 2019, Google dejó muy claro que este comando no es compatible.
Si quieres excluir de forma fiable una página o un archivo de los resultados de la búsqueda, evita por completo este comando y utiliza una etiqueta noindex.
Cómo crear un archivo robots.txt
Si aún no tienes un archivo robots.txt, puedes crearlo en pocos pasos.
Puedes utilizar una herramienta generadora de archivos robots.txt, o puedes crear uno tú mismo.
A continuación te explicamos cómo crear un archivo robots.txt en solo cuatro pasos:
- Crea un archivo y llámalo robots.txt.
- Añade comandos al archivo robots.txt.
- Sube el archivo a tu web.
- Prueba el archivo.
1. Crea un archivo y nómbralo robots.txt
Empieza abriendo un documento .txt con cualquier editor de texto o navegador web.
Nota: no uses un procesador de textos, ya que a menudo guardan los archivos en un formato propietario que puede añadir caracteres aleatorios.
A continuación, nombra el documento robots.txt. Debe llamarse robots.txt para que funcione.
Ya estás listo para empezar a escribir comandos.
2. Añade comandos al archivo robots.txt
Un archivo robots.txt está formado por uno o varios grupos de comandos, y cada grupo consta de varias líneas de instrucciones.
Cada grupo comienza con un "User-agent" y tiene la siguiente información:
- A quién se aplica el grupo (el User-agent).
- A qué directorios (páginas) o archivos puede acceder el agente.
- A qué directorios (páginas) o archivos no puede acceder el agente.
- Un sitemap (opcional) para indicar a los motores de búsqueda qué páginas y archivos consideras importantes.
Los rastreadores ignoran las líneas que no coinciden con ninguna de estas directivas.
Por ejemplo, digamos que quieres evitar que Google rastree tu directorio /clients/ porque es para uso interno.
El primer grupo sería algo así:
User-agent: Googlebot
Disallow: /clients/Si tuvieras más instrucciones como esta para Google, las incluirías en una línea separada justo debajo, así:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-googleUna vez que hayas terminado con las instrucciones específicas de Google, puedes pulsar dos veces la tecla "Enter" para crear un nuevo grupo de comandos.
Vamos a crear un grupo de comandos para todos los motores de búsqueda y evitemos que rastreen tus directorios /archive/ y /support/ porque son privados y de uso interno.
Tendría el siguiente aspecto:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/Una vez que hayas terminado, puedes añadir tu sitemap.
Tu archivo robots.txt terminado tendría el siguiente aspecto:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/
Sitemap: https://www.yourwebsite.com/sitemap.xmlGuarda tu archivo robots.txt. Recuerda que debe llamarse robots.txt.
Nota: los rastreadores leen de arriba a abajo y coinciden con el primer grupo de comandos más específico. Por tanto, empieza tu archivo robots.txt con user agents específicos, y luego pasa al comodín más general (*) que coincide con todos los rastreadores.
3. Sube el archivo robots.txt
Una vez que hayas guardado tu archivo robots.txt en tu ordenador, súbelo a tu web y ponlo a disposición de los motores de búsqueda para que lo rastreen.
Por desgracia, no existe ninguna herramienta universal que pueda ayudar en este paso.
La carga del archivo robots.txt depende de la estructura de archivos de tu web y del alojamiento.
Busca en internet o acude a tu proveedor de hosting para que te ayude a subir tu archivo robots.txt.
Por ejemplo, puedes buscar "subir el archivo robots.txt a WordPress" para conseguir instrucciones específicas.
Aquí tienes algunos artículos que explican cómo subir tu archivo robots.txt en las plataformas más populares:
- Archivo robots.txt en WordPress
- Archivo robots.txt en Wix
- Archivo robots.txt en Joomla
- Archivo robots.txt en Shopify
- Archivo robots.txt en BigCommerce
Después de subir el archivo robots.txt, comprueba si alguien puede verlo y si Google puede leerlo.
Así es cómo se hace.
4. Prueba tu robots.txt
En primer lugar, verifica si tu archivo robots.txt es accesible públicamente (es decir, si se ha subido correctamente).
Abre una ventana privada en tu navegador y busca tu archivo robots.txt.
Por ejemplo, https://semrush.com/robots.txt.
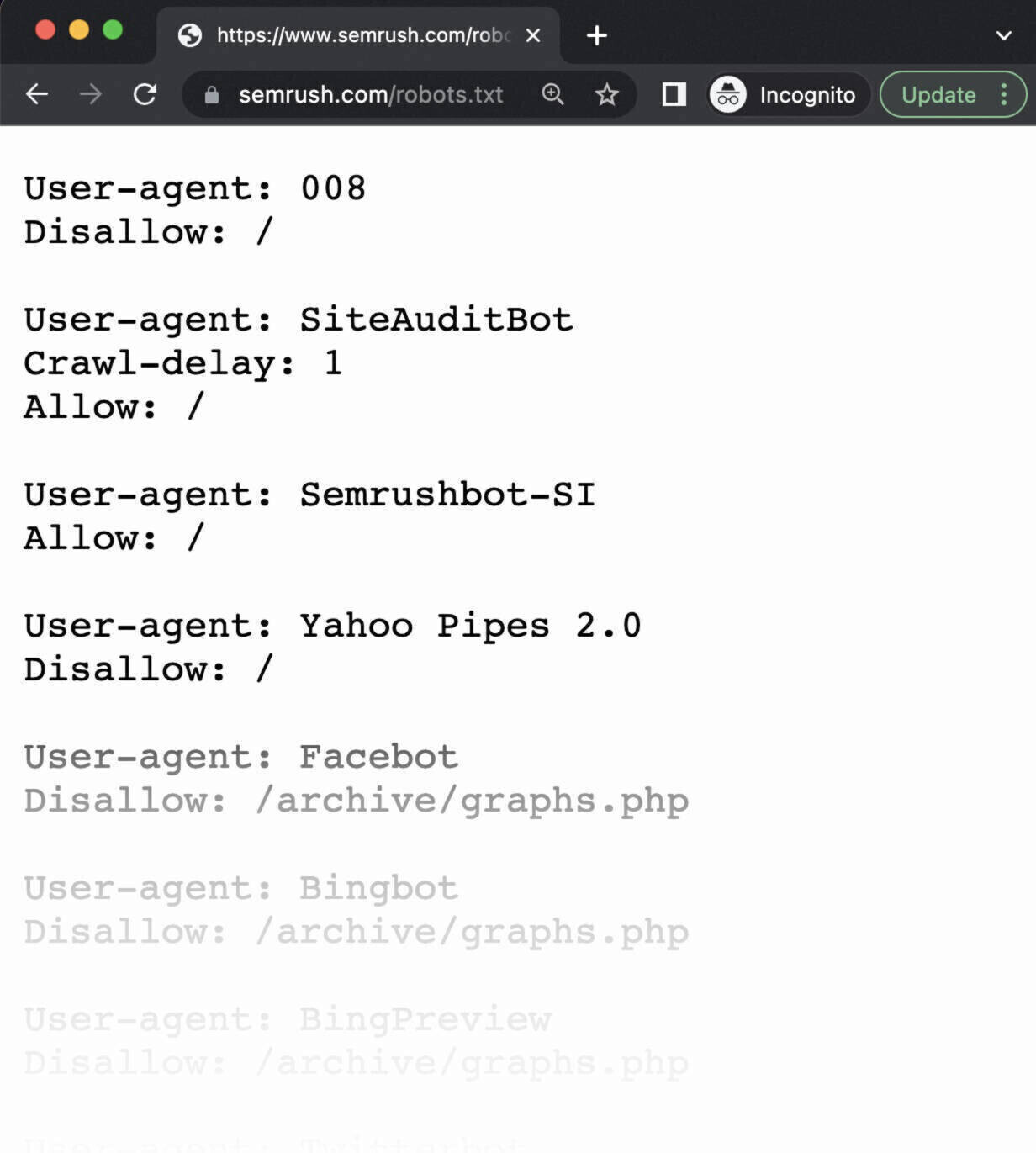
Si ves tu archivo robots.txt con el contenido que has añadido, estás listo para probar el marcado (código HTML).
Google ofrece dos opciones para comprobar el marcado robots.txt:
- El comprobador de robots.txt en Search Console.
- Biblioteca robots.txt de código abiertode Google (avanzado).
Como la segunda opción está más orientada a desarrolladores avanzados, vamos a probar tu archivo robots.txt en Search Console.
Nota: debes tener una cuenta de Search Console configurada para probar tu archivo robots.txt.
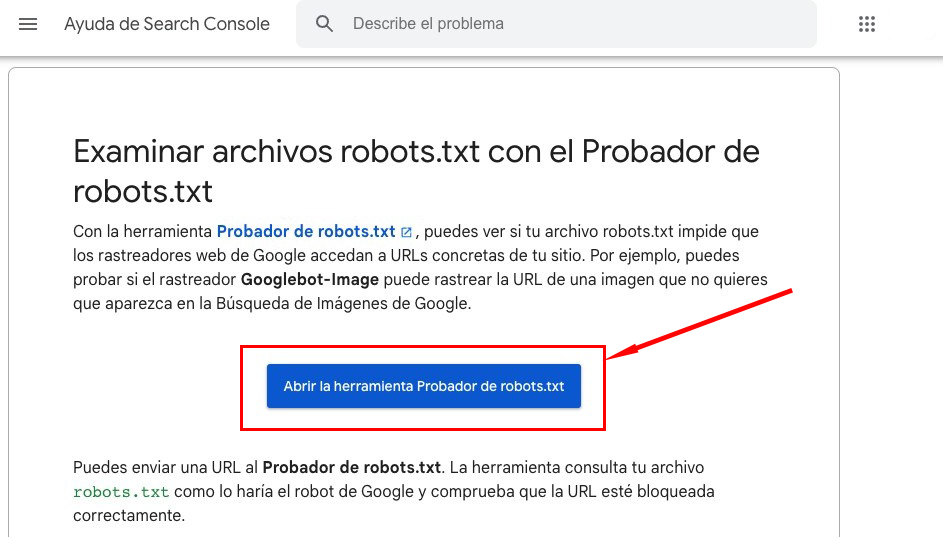
Ve al comprobador de robots.txt y haz clic en "Abrir el comprobador de robots.txt".
Si no has vinculado tu web a tu cuenta de Google Search Console, tendrás que añadir primero una propiedad.

A continuación, tendrás que verificar que eres el verdadero propietario del sitio.

Si ya tienes propiedades verificadas, selecciona una de la lista desplegable de la página de inicio del Comprobador.

El Verificador identificará las advertencias de sintaxis o los errores lógicos y los resaltará.
También te mostrará el número de advertencias y errores inmediatamente debajo del editor.
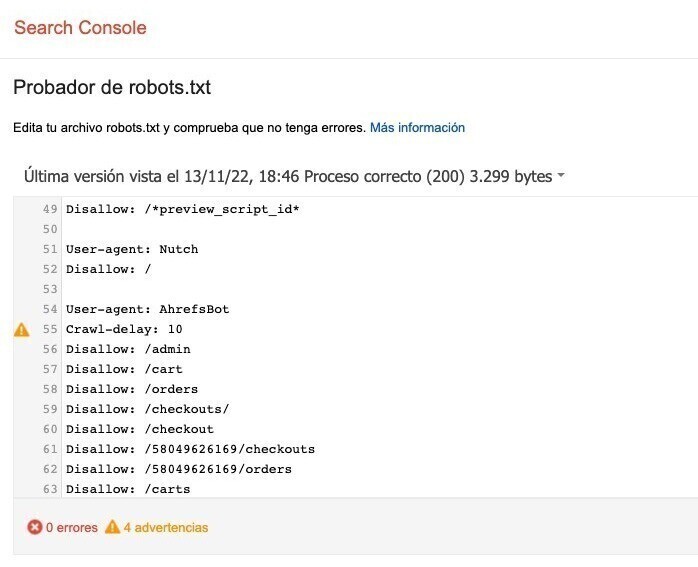
Puedes editar los errores o las advertencias directamente en la página y volver a probar tantas veces como sea necesario.
Ten en cuenta que los cambios realizados en la página no se guardan en tu web. La herramienta no realiza ningún cambio en el archivo real de tu sitio. Solo comprueba la copia alojada en la herramienta.
Para aplicar los cambios, cópialos y pégalos en el archivo robots.txt de tu web.
Consejo profesional: define auditorías técnicas de SEO mensuales con la herramienta Auditoría del sitio de Semrush para revisar si hay nuevos problemas relacionados con tu archivo robots.txt. Es importante vigilar tu archivo, ya que incluso pequeños cambios pueden afectar negativamente a la indexabilidad de tu sitio.
Haz clic aquí para ver la herramienta de Auditoría del sitio de Semrush.
Ten en cuenta estas buenas prácticas al crear tu archivo robots.txt para evitar los errores más comunes.
Utiliza nuevas líneas para cada comando
Cada comando debe estar en una nueva línea.
De lo contrario, los motores de búsqueda no podrán leerlos, y tus instrucciones serán ignoradas.
Mal:
User-agent: * Disallow: /admin/
Disallow: /directory/Bien:
User-agent: *
Disallow: /admin/
Disallow: /directory/Utiliza cada user-agent una vez
A los robots no les importa que introduzcas el mismo user-agent varias veces.
Pero, al mencionarlo solo una vez, las cosas se mantienen ordenadas y sencillas y se reduce la posibilidad de error humano.
Mal:
User-agent: Googlebot
Disallow: /example-page
User-agent: Googlebot
Disallow: /example-page-2Observa que el user-agent de Googlebot aparece dos veces.
Bien:
User-agent: Googlebot
Disallow: /example-page
Disallow: /example-page-2En el primer ejemplo, Google seguiría las instrucciones y no rastrearía ninguna de las dos páginas.
Pero escribir todos las comandos bajo el mismo User-agent es más limpio y te ayuda a mantenerte organizado.
Utiliza los comodines para aclarar las indicaciones
Puedes utilizar comodines (*) para aplicar un comando a todos los user-agent y que coincida con patrones de URL.
Por ejemplo, si quieres impedir que los motores de búsqueda accedan a las URL con parámetros, técnicamente podrías enumerarlos uno por uno.
Mal:
User-agent: *
Disallow: /shoes/vans?
Disallow: /shoes/nike?
Disallow: /shoes/adidas?No es práctico. Puedes simplificar tus direcciones con un comodín.
Bien:
User-agent: *
Disallow: /shoes/*?El ejemplo anterior bloquea a todos los robots de los motores de búsqueda para que no rastreen todas las URL de la subcarpeta /zapatos/ con un signo de interrogación.
Utilizar "$" para indicar el final de una URL
Añadir el "$" indica el final de una URL.
Por ejemplo, si quieres impedir que los motores de búsqueda rastreen todos los archivos .jpg de tu sitio, puedes listarlos individualmente.
Pero no sería muy práctico.
Mal:
User-agent: *
Disallow: /photo-a.jpg
Disallow: /photo-b.jpg
Disallow: /photo-c.jpgSería mucho mejor utilizar la función "$" así:
Bien:
User-agent: *
Disallow: /*.jpg$Nota: en este ejemplo, /dog.jpg no puede ser rastreado, pero /dog.jpg?p=32414 sí porque no termina en ".jpg".
La expresión "$" es una característica útil en circunstancias específicas como las anteriores, pero también puede ser peligrosa.
Puedes desbloquear fácilmente cosas que no querías, así que sé prudente a la hora de aplicarlo.
Utiliza el guion (#) para añadir comentarios
Los rastreadores ignoran todo lo que comienza con una almohadilla (#).
Por ello, los desarrolladores suelen utilizarlo para añadir un comentario en el archivo robots.txt. Ayuda a que el archivo esté organizado y sea fácil de leer.
Para incluir un comentario, comienza la línea con una almohadilla (#).
Así:
User-agent: *
#Landing Pages
Disallow: /landing/
Disallow: /lp/
#Files
Disallow: /files/
Disallow: /private-files/
#Websites
Allow: /website/*
Disallow: /website/search/*Los desarrolladores incluyen de vez en cuando mensajes divertidos en los archivos robots.txt porque saben que los usuarios rara vez los ven.
Por ejemplo, el archivo https://www.youtube.com/robots.txt dice
"Creado en un futuro lejano (el año 2000) tras el levantamiento robótico de mediados de los 90 que acabó con todos los humanos".

Y el robots.txt de Nike dice "just crawl it" (un guiño a su eslogan "just do it") y también incluye su logotipo.

Utiliza archivos robots.txt distintos para diferentes subdominios
Los archivos robots.txt solo controlan el comportamiento de rastreo en el subdominio donde están alojados.
Por lo tanto, si quieres controlar el rastreo en un subdominio diferente, necesitas un archivo robots.txt separado.
Así que si tu sitio principal vive en el dominio.com y tu blog vive en el subdominio blog.dominio.com, necesitarías dos archivos robots.txt.
Uno para el directorio raíz del dominio principal y otro para el directorio raíz de tu blog.
Sigue aprendiendo
Ahora que ya sabes cómo funcionan los archivos robots.txt, aquí tienes otros artículos que puedes consultar para seguir aprendiendo: