Uno de los retos de SEO técnico más comunes a los que se enfrentan los SEOs es conseguir que Google indexe el contenido JavaScript.
El uso de JavaScript crece rápidamente. Está bien documentado que muchas webs tienen problemas con el crecimiento orgánico debido a que no prestan atención a la importancia del SEO JavaScript.
Si trabajas con webs que se han desarrollado en entornos JavaScript (como React, Angular o Vue.js), inevitablemente te enfrentarás a retos diferentes de los que usan Wordpress, Shopify u otros CMSs populares.
Sin embargo, para lograr tener éxito en los motores de búsqueda, debes saber con exactitud cómo comprobar que tus páginas pueden ser renderizadas e indexadas, identificar problemas y asegurarte de que son amigables para los motores de búsqueda.
En esta guía, vamos a enseñarte todo lo que necesitas saber sobre SEO JavaScript. En concreto, vamos a repasar:
- ¿Qué es JavaScript?
- ¿Qué es el SEO JavaScript?
- ¿Cómo rastrea e indexa Google el JavaScript?
- Cómo hacer que el contenido JavaScript de tu web sea SEO-friendly
- Renderizado del lado del Servidor vs. Renderizado del lado del Cliente vs. Renderizado Dinámico
- Problemas comunes con SEO JavaScript y cómo evitarlos
¿Qué es JavaScript?
JavaScript o JS es un lenguaje de programación (o scripting) para webs. JavaScript se combina con HTML y CSS para ofrecer un nivel de interactividad que de otro modo no sería posible. Para la mayoría de las webs, significa gráficos animados y controles deslizantes, formularios interactivos, mapas, juegos basados en la web y otras funciones interactivas.
Pero es cada vez más común que webs completas se creen utilizando marcos de JavaScript como React o Angular, que se pueden usar para impulsar aplicaciones móviles y web. Y el hecho de que estos marcos puedan crear aplicaciones web de una sola página y de varias páginas los ha hecho cada vez más populares entre los desarrolladores.
¿Qué es el SEO JavaScript?
El SEO JavaScript es una parte del SEO técnico que implica facilitar que los motores de búsqueda rastreen e indexen JavaScript.
El SEO para webs JavaScript tiene sus propios desafíos únicos. Y estos procesos deben seguirse para maximizar las posibilidades de posicionamiento y hacer que los motores de búsqueda indexen las páginas de tu web.
Por lo tanto, es fácil caer en errores muy comunes cuando se trabaja con webs JavaScript. Habrá muchas más idas y venidas con los desarrolladores para garantizar que todo se haga correctamente.
Sin embargo, JavaScript está ganando popularidad y, como SEO, comprender cómo optimizar estos sitios correctamente es una habilidad importante que debes aprender.
¿Cómo rastrea e indexa Google el JavaScript?
Dejemos una cosa clara: Google es ahora mejor renderizando JavaScript que hace unos años, cuando normalmente tardaba semanas.
Pero antes de profundizar en las formas que el JavaScript de tu web sea compatible con el SEO y pueda ser rastreado e indexado, debemos comprender cómo lo procesa Google. Se trata de un proceso en tres fases:
-
Rastreo
-
Renderizado
-
Indexación
Puedes ver este proceso visualizado con más detalle a continuación:
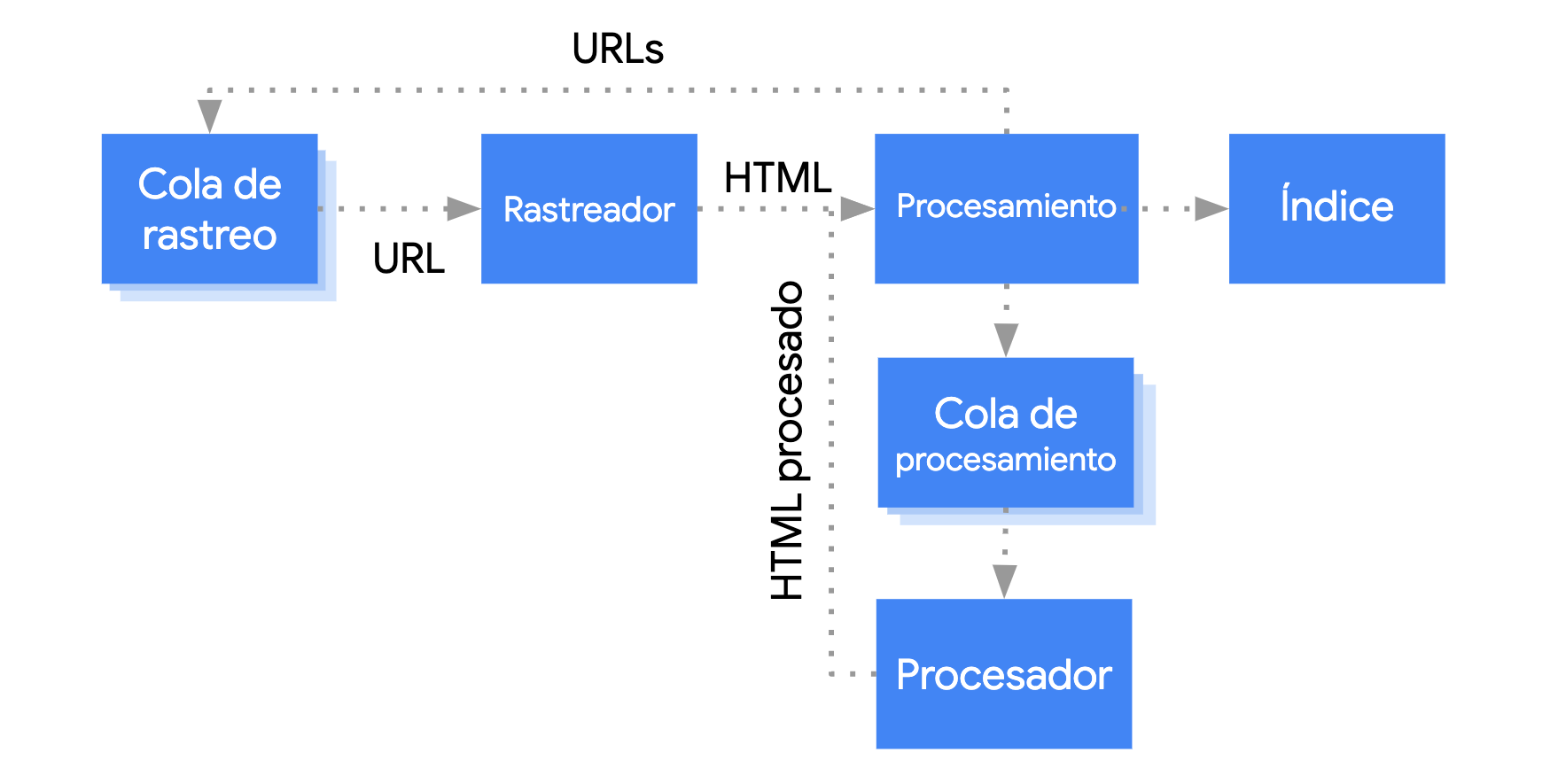 Fuente: Google
Fuente: Google
Vamos a echar un vistazo a este proceso un poco más en detalle. Y lo vamos a comparar con cómo el Googlebot rastrea una página HTML.
Es un proceso rápido y simple que empieza con la descarga de archivos, la extracción de enlaces, y de los archivos CSS antes de que estas fuentes se envíen a Caffeine, el indexador de Google. Caffeine, a continuación, indexa la página.
Al igual que con una página HTML, el proceso comienza con la descarga de un archivo HTML. Después, se descargan los enlaces generados por JavaScript, que no se pueden extraer de la misma manera. Por lo que Googlebot descarga los archivos CSS y JS de la página y después necesita usar el Servicio de Renderización Web (WRS), parte de Caffeine, para indexar este contenido. Posteriormente, el WRS podrá indexar el contenido y extraer enlaces.
La realidad es que es un proceso complicado que requiere más tiempo y recursos que en una página HTML. Y Google no puede indexar el contenido hasta que el JavaScript ya haya sido renderizado.
Rastrear una web HTML es rápido y eficaz: el Googlebot descarga el HTML, extrae los enlaces de la página y los rastrea. Pero cuando el JavaScript está involucrado, no sucede de la misma manera, ya que debe ser renderizado antes de que los enlaces puedan ser extraídos.
Vamos a echarle un vistazo a las formas de que el contenido de tu web JavaScript sea SEO-friendly.
Cómo hacer que el contenido JavaScript de tu web sea SEO-friendly
Google debe poder rastrear y renderizar tu web JavaScript para poder indexarla. Sin embargo, es usual que se presenten retos que impidan la indexación.
Cuando se trata de asegurarse de que tu web JavaScript sea SEO friendly, hay varios pasos que puedes seguir para asegurarte que tu contenido está siendo renderizado e indexado.
Y realmente, se reduce a tres cosas:
-
Asegurarse de que Google puede rastrear el contenido de tu web
-
Asegurarse de que Google puede renderizar el contenido de tu web
-
Asegurarse de que Google puede indexar el contenido de tu web
Hay varios pasos que puedes dar para asegurarte de que estos tres pasos sucedan, así como formas de mejorar el contenido JavaScript para los motores de búsqueda.
Veamos de qué se trata.
Asegúrate de que Google pueda renderizar tus páginas usando Google Search Console
A pesar de que Googlebot está basado en la versión de Chrome más reciente, no se comporta de la misma manera que un buscador. Eso significa que, a pesar de que tu web se pueda abrir en el buscador, el contenido web no tiene por qué poder ser renderizado.
Puedes utilizar la herramienta de Inspección de URLs en Google Search Console para comprobar que Google puede renderizar tu web.
Introduce la URL de la página que deseas comprobar y observa el botón en la parte superior derecha de tu pantalla de "Prueba en tiempo real".

Después de un minuto o dos, verás una pestaña de "prueba en tiempo real". Al hacer clic en "ver página probada" verás una captura de la página que muestra cómo Google la ha renderizado. Puedes ver también el código renderizado en la pestaña de HTML.
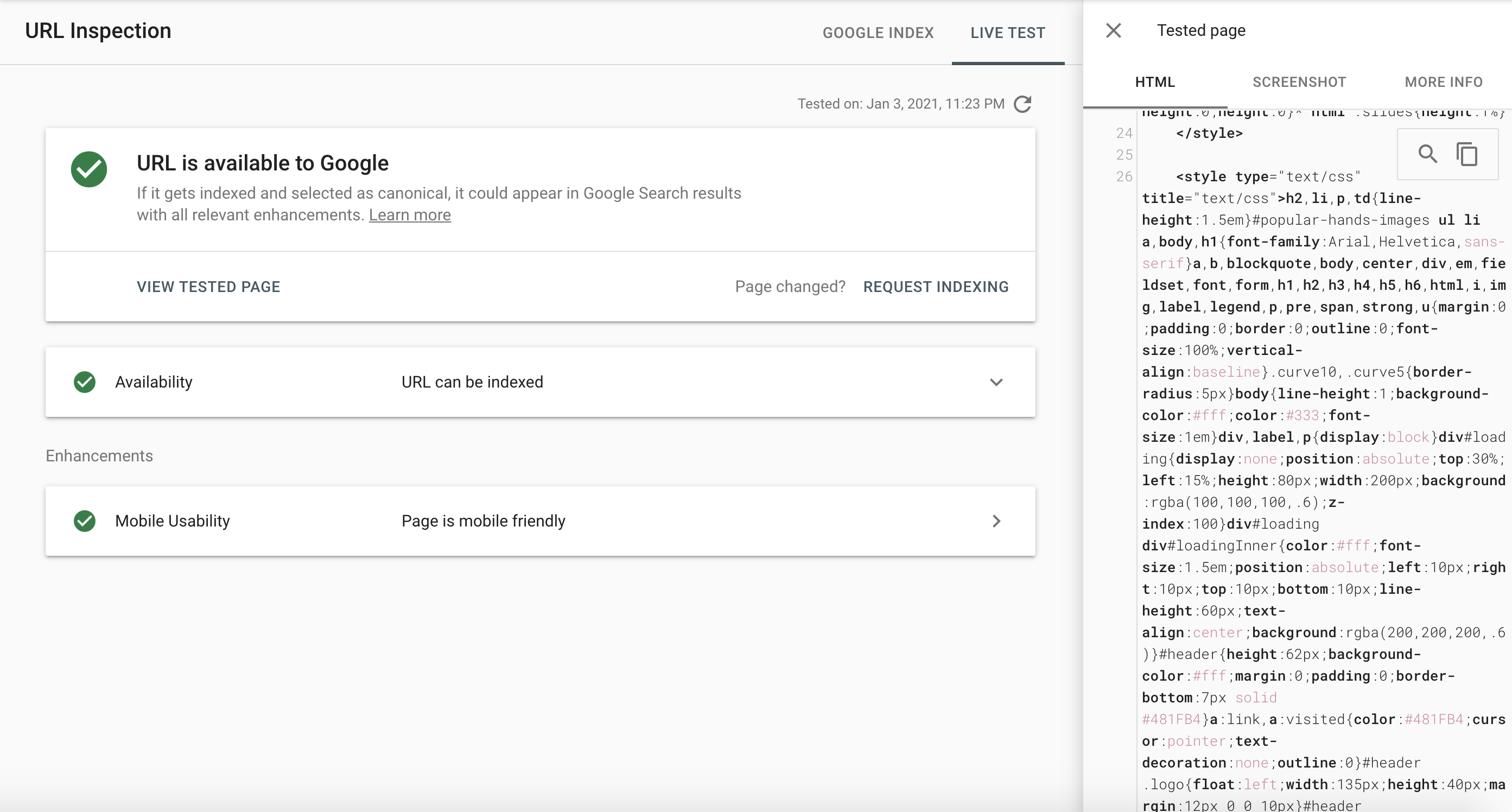
Comprueba cualquier discrepancia o contenido ausente, ya que puede significar que determinados recursos (incluido JavaScript) están bloqueados, y que hay errores o tiempos de espera. Haz clic en la pestaña "más info" para ver cualquier error, y para ayudarte a determinar la causa.
La razón más común por la que Google no puede renderizar las páginas JavaScript
La razón más común por la que Google no puede renderizar las páginas JavaScript es porque estos recursos están bloqueados en el archivo robots.txt de tu sitio, y con frecuencia accidentalmente.
Añade el siguiente código a este archivo para asegurarte de que no hay recursos cruciales que se están bloqueando al rastreo:
User-Agent: Googlebot
Allow: .js
Allow: .cssNo obstante, vamos a dejar una cosa clara; Google no indexa archivos .js o .css en los resultados de búsqueda. Estos recursos se usan para renderizar una web.
No hay razón para bloquear recursos cruciales, y hacerlo podría evitar que tu contenido sea renderizado y, en consecuencia, indexado.
Asegúrate que Google esté indexando tu contenido JavaScript
Si has confirmado que tu web está renderizada adecuadamente, necesitas determinar si está siendo o no indexada.
Puedes comprobarlo mediante Google Search Console, y también directamente en el motor de búsqueda.
Ve a Google y utiliza el comando site: para ver si tu página está en el índice. Como ejemplo, reemplaza tudominio.com por la URL de la página que quieres comprobar:
site:tudominio.com/pagina-URL/Si la página está en el índice de Google, verás que se muestra la página como un resultado:
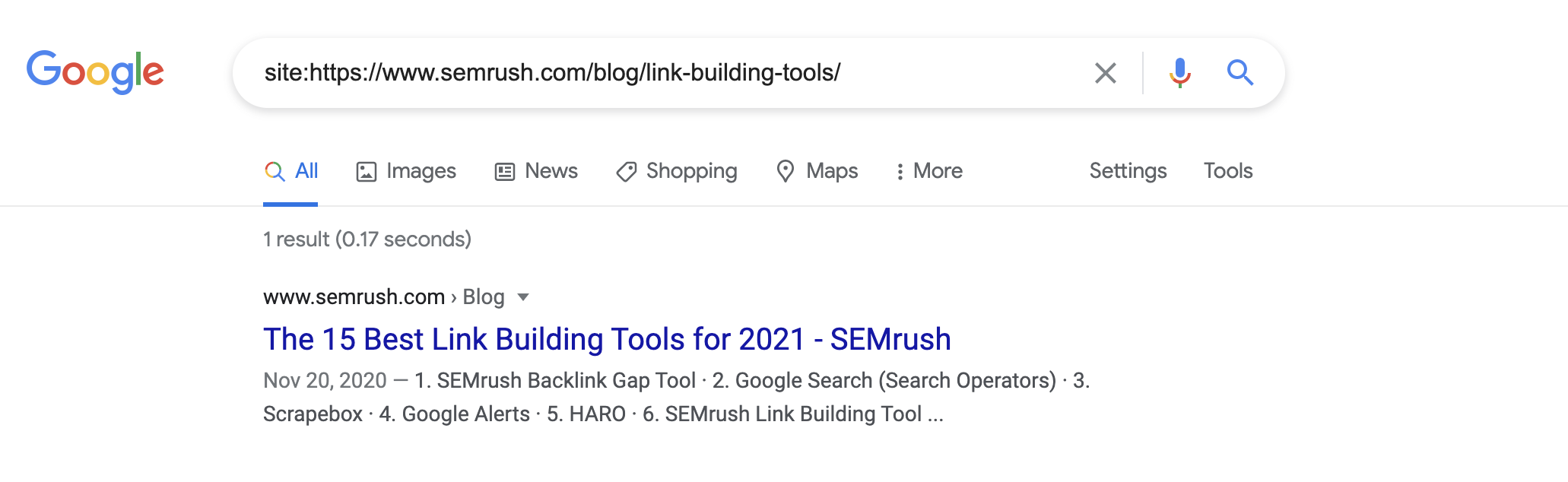
Si no ves la URL, significa que la página no está en el índice.
Luego de comprobar que se encuentra en el índice, comprueba si una sección de contenido generado JavaScript está o no indexado.
Una vez más, utiliza el comando site: e incluye un fragmento del contenido. Por ejemplo:
site:yourdomain.com/page-URL/ "fragmento de contenido JS"Aquí, estás comprobando tanto si el contenido ha sido indexado como, si lo está, puedes ver este texto dentro del fragmento.
También puedes analizar si el contenido JavaScript está indexado usando Google Search Console, nuevamente usando la Herramienta de Inspección de URLs.
Esta vez, en lugar de probar la URL en directo, haz clic en el botón de "probar URL publicada" y podrás ver el código fuente de la página HTML indexada.
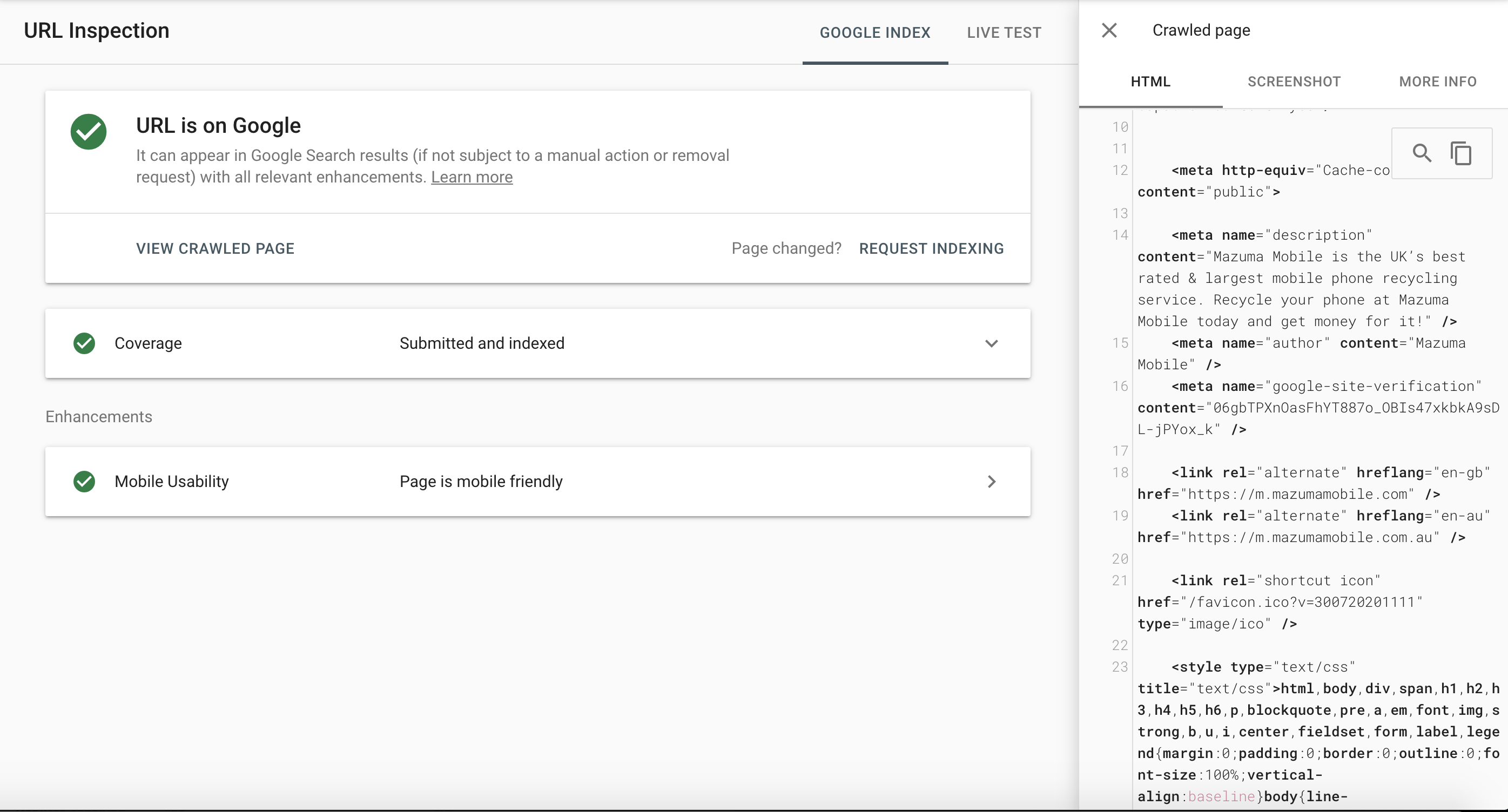
Escanea el código HTML para fragmentos de contenido que sabes que han sido generados con JavaScript.
Razones frecuentes por las que Google no puede indexar contenido JavaScript
Puede haber muchos motivos por los que Google no es capaz de indexar tu contenido JavaScript, estos pueden ser:
-
El contenido no puede ser renderizado en primera instancia
-
La URL no puede ser encontrada debido a que los enlaces han sido generados mediante JavaScript en un evento clic
-
La página ha agotado su tiempo mientras Google indexa el contenido
-
Google determina que los recursos JS no cambian la página lo suficiente como para justificar ser descargada
A continuación, veremos las soluciones a algunos de estos problemas comunes.
Renderizado del lado del Servidor vs. Renderizado del lado del Cliente vs. Renderizado Dinámico
Si tienes o no problemas con la indexación en Google, tu contenido de JavaScript se ve afectado en gran medida por la forma en que su sitio representa este código. Y debes comprender las diferencias entre el renderizado del lado del servidor, el renderizado del lado del cliente y el renderizado dinámico.
Como SEOs, necesitamos aprender a trabajar con desarrolladores para superar los retos de trabajar con JavaScript. Mientras que Google continúa mejorando la forma en que rastrea, renderiza e indexa contenido generado mediante JavaScript, puedes evitar que muchas de las situaciones ya experimentadas se conviertan en problemas.
De hecho, comprender las diferentes formas de renderizado JavaScript es probablemente la única cosa importante que necesitas saber sobre el SEO JavaScript.
¿Cuáles son los diferentes tipos de renderizado y qué significan?
Renderizado del lado del servidor (SSR) es cuando el JavaScript se renderiza en el servidor y una página HTML se sirve al cliente (el buscador, el Googlebot, etc.). El proceso para que la página sea rastreada e indexada es igual a cualquier página HTML como hemos descrito arriba y los problemas específicos JavaScript no deberían existir.
Según Free Code Camp, así es cómo funciona el SSR: "Siempre que visitas una web, tu navegador realiza una solicitud al servidor con los contenidos del sitio. Una vez que se procesa la respuesta, tu navegador consigue de vuelta un HTML completamente renderizado y lo presenta en la pantalla."
El problema aquí es que el SSR puede ser complejo y desafiante para los desarrolladores. Sin embargo, herramientas como Gatsby y Next.JS (para el framework React), Angular Universal (para el framework Angular) o Nuxt.js (para el framework Vue.js) pueden ayudar a implementarlo.
Renderizado del lado del cliente (CSR) es prácticamente el polo opuesto de SSR y donde el cliente (navegador o Googlebot, en este caso) renderiza el JavaScript utilizando el DOM. Cuando el cliente tiene que renderizar JavaScript, los desafíos descritos anteriormente pueden existir cuando el Googlebot intenta rastrear, renderizar e indexar contenido.
Una vez más, según Free Code Camp, "cuando los desarrolladores hablan de renderizado del lado del cliente, hablan de contenido renderizado en el navegador usando JavaScript. Entonces, en lugar de obtener todo el contenido del documento HTML en sí, estás consiguiendo un documento HTML básico con un archivo JavaScript que procesará el resto del sitio usando el navegador".
Una vez se comprende cómo funciona el CRS, es fácil ver por qué pueden aparecer los problemas de SEO.
Renderizado dinámico es una alternativa al renderizado del lado del servidor. También es una solución viable para entregar a los usuarios una web que contenga contenido JavaScript en el navegador, mientras se entrega una versión estática al Googlebot.
Es algo que comentó John Mueller de Google en Google I/O en 2018:

Piensa en ello como un envío de contenido renderizado del lado del cliente a los usuarios en el buscador y como contenido renderizado del lado del servidor a los motores de búsqueda. Es algo que soporta y recomienda Bing y que se puede conseguir con herramientas como prerender.io, una herramienta que se describe a sí misma como "el rocket science para JavaScript SEO". Puppeteer y Rendertron son otras alternativas.
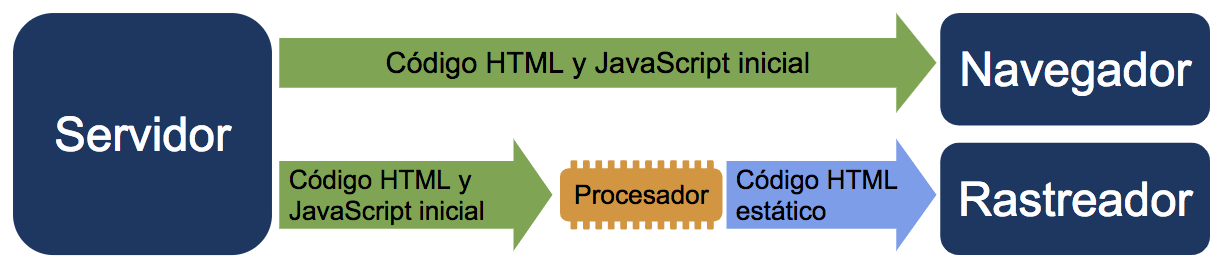 Fuente: Google
Fuente: Google
Para aclarar una pregunta que probablemente tendrán muchos SEOs: el renderizado dinámico no se considera encubrimiento siempre que el contenido que se ofrezca sea similar. El único momento en el que se consideraría encubrimiento es si se muestra contenido completamente diferente. Con el renderizado dinámico, el contenido que ven los usuarios y los motores de búsqueda será el mismo, únicamente con diferentes niveles de interactividad.
Puedes aprender más sobre cómo configurar el renderizado dinámico aquí.
Problemas comunes con SEO JavaScript y cómo evitarlos
Es frecuente tener que encarar problemas de SEO provocados por JavaScript, a continuación encontrarás algunos de los más comunes, y te presentamos algunos consejos sobre cómo evitarlos.
-
Bloquear los archivos .js en tu archivo robots.txt puede evitar que el Googlebot rastree esos recursos y, como consecuencia, que los renderice y los indexe. Permite que estos archivos puedan ser rastreados para evitar problemas.
-
Normalmente, Google no espera mucho tiempo para renderizar contenido JavaScript, y si se retrasa, encontrarás que el contenido no se ha indexado debido a un error de tiempo de espera agotado.
-
Cuando la configuración de la paginación se determina para que el resto de las páginas (excepto la primera, por ejemplo, en una categoría de eCommerce) se den con un evento clic (clics) esto tiene como resultado que las páginas posteriores no se rastreen, ya que los motores de búsqueda no hacen clic en los botones. Asegúrate siempre de utilizar enlaces estáticos para ayudar al robot de Google a descubrir las páginas de tu sitio.
-
Cuando se carga una página de forma diferida con JavaScript, asegúrate de no retrasar la carga de contenido que debería indexarse. Por lo general, debe usarse para imágenes en lugar de contenido de texto.
-
El JavaScript renderizado del lado del cliente no puede devolver errores del servidor de la misma forma que el contenido renderizado del lado del servidor. Por ejemplo, redirigir errores a una página que devuelve un código de estado 404.
-
Asegúrate de que se generen URLs estáticas para las páginas de tu sitio, en lugar de usar #. Así, se garantiza que tus URLs se vean así (tudominio.com/pagina-web) y no así (tudominio.com/#/pagina-web) o así (tudominio.com#pagina-web). Utiliza URL estáticas. De lo contrario, estas páginas no se indexarán, ya que Google normalmente ignora los hash.
En definitiva, no hay que negar que JavaScript puede causar problemas para rastrear e indexar tu contenido web. Sin embargo, comprender el por qué y conocer la mejor manera de trabajar con el contenido generado de esta manera, puede reducir enormemente estos problemas.
Se necesita tiempo para familiarizarse completamente con JavaScript. Pero a pesar de que Google mejora su indexación, es importante que mejores tus conocimientos y experiencia en el tema para atender los problemas que se presenten.
Otras lecturas recomendadas sobre SEO JavaScript:
- Google Search Central: comprender los aspectos básicos de SEO JavaScript