¿No funciona correctamente Auditoría del sitio?
Hay varias razones por las que las páginas pueden quedar bloqueadas para el rastreador de Auditoría del sitio en función de la configuración y estructura de tu sitio web, entre ellas:
- Robots.txt bloquea el rastreo
- El alcance del rastreo excluye ciertas partes del sitio
- El sitio web no está directamente en línea debido al alojamiento compartido
- El tamaño de la página de destino es superior a 2 MB
- Las páginas están protegidas por una pasarela o un requisito de inicio de sesión
- Rastreador bloqueado por etiqueta noindex
- No se ha podido resolver el dominio mediante DNS; el dominio introducido en la configuración está desconectado
- El contenido del sitio web está basado en JavaScript: aunque Auditoría del sitio puede procesar código JS, este puede provocar algunos problemas
Pasos para solucionar problemas
Sigue estos pasos de solución de problemas para ver si puedes hacer algún ajuste por tu cuenta antes de ponerte en contacto con nuestro equipo de asistencia para que te ayude.
Un archivo Robots.txt da instrucciones a los robots sobre cómo rastrear (o no rastrear) las páginas de un sitio web. Puedes permitir y prohibir que robots como Googlebot o Semrushbot rastreen todo tu sitio o áreas específicas del mismo utilizando comandos como Permitir, No permitir y Retraso del rastreo.
Si tu archivo robots.txt impide que nuestro robot rastree tu sitio, nuestra herramienta de auditoría de sitios no podrá revisarlo.
Puedes inspeccionar tu Robots.txt en busca de comandos disallow que impidan a rastreadores como el nuestro acceder a tu sitio web.
Para permitir que el bot de Auditoría del sitio de Semrush (SiteAuditBot) rastree tu sitio, añade lo siguiente a tu archivo robots.txt:
User-agent: SiteAuditBot
Disallow:
(deja un espacio en blanco después de "Disallow:")
Aquí tienes un ejemplo de cómo puede ser un archivo robots.txt:

Observa los distintos comandos en función del agente de usuario (rastreador) al que se dirige el archivo.
Estos archivos son públicos y para que puedan encontrarse deben estar alojados en el nivel superior de un sitio. Para encontrar el archivo robots.txt de un sitio web, introduce en tu navegador el dominio raíz de un sitio seguido de /robots.txt. Por ejemplo, el archivo robots.txt de Semrush.com se encuentra en https://semrush.com/robots.txt.
Algunos términos que puedes ver en un archivo robots.txt incluyen:
- User-Agent = el rastreador web al que estás dando instrucciones.
- Ej: SiteAuditBot, Googlebot
- Permitir = un comando (sólo para Googlebot) que indica al robot que puede rastrear una página o área específica de un sitio, incluso si la página o carpeta principal se excluye del rastreo.
- Disallow = un comando que indica al bot que no rastree una URL o subcarpeta específica de un sitio.
- Ej: Disallow: /admin/
- Retraso de rastreo = un comando que indica a los robots cuántos segundos deben esperar antes de cargar y rastrear otra página.
- Mapa del sitio = indica dónde está el archivo sitemap.xml de una URL determinada.
- / = utiliza el símbolo "/" después de un comando disallow para indicar al bot que no rastree la totalidad de tu sitio web
- * = un símbolo comodín que representa cualquier cadena de caracteres posibles en una URL, utilizado para indicar un área de un sitio o todos los agentes de usuario.
- Ej: Disallow: /blog/* indicaría todas las URL de la subcarpeta blog de un sitio
- Ej: Agente de usuario: * indicaría instrucciones para todos los bots
Más información sobre las especificaciones de Robots.txt en Google o en el blog de Semrush.
Si ves el siguiente código en la página principal de un sitio web, indica que no se nos permite indexarlo o no podemos rastrear sus enlaces, y tenemos bloqueado el acceso al sitio.
meta name="robots" content="noindex, nofollow"
O bien, el error de rastreo lo provoca una página cuyo código contiene elementos "noindex", "nofollow", "none".
Para permitir que nuestro bot rastree la página, elimina las etiquetas "noindex" del código de tu página. Para más información sobre la etiqueta noindex, consulta este artículo de soporte de Google.
Para incluir al bot en la lista blanca, ponte en contacto con tu webmaster o proveedor de alojamiento y pídele que incluya a SiteAuditBot en la lista blanca.
Las direcciones IP del bot son: 85.208.98.128/25 (una subred utilizada solo por Auditoría del sitio).
El bot utiliza los puertos estándar 80 HTTP y 443 HTTPS para conectarse.
Si utilizas plugins (Wordpress, por ejemplo) o CDN (redes de distribución de contenidos) para gestionar tu sitio, también tendrás que incluir la IP del bot en ellos.
Para crear listas blancas en Wordpress, ponte en contacto con soporte de Wordpress.
Entre las CDN habituales que bloquean nuestro rastreador se incluyen:
- Cloudflare - descubre cómo añadirlo a la lista blanca aquí
- Imperva - descubre cómo añadirlo a la lista blanca aquí
- ModSecurity - descubre cómo añadirlo a la lista blanca aquí
- Sucuri - descubre cómo añadirlo a la lista blanca aquí
Nota: Si tienes un alojamiento compartido, es posible que tu proveedor de alojamiento no te permita incluir robots en la lista blanca ni editar el archivo Robots.txt.
Proveedores de alojamiento
A continuación encontrarás una lista de algunos de los proveedores de alojamiento más populares de la red y cómo poner un bot en la lista blanca de cada uno de ellos o contactar con su equipo de soporte para obtener ayuda:
- Siteground - instrucciones para listas blancas
- 1&1 IONOS - instrucciones para listas blancas
- Bluehost* - instrucciones para listas blancas
- Hostgator* - instrucciones para listas blancas
- Hostinger - instrucciones para listas blancas
- GoDaddy - instrucciones para listas blancas
- GreenGeeks - instrucciones para listas blancas
- Big Commerce - Debes ponerte en contacto con soporte
- Liquid Web - Debes ponerte en contacto con soporte
- iPage - Debes ponerte en contacto con soporte
- InMotion - Debes ponerte en contacto con soporte
- Glowhost - Debes ponerte en contacto con soporte
- Hosting – Debes ponerte en contacto con soporte
- DreamHost - Debes ponerte en contacto con soporte
* Nota: estas instrucciones funcionan para HostGator y Bluehost si tienes un sitio web en el VPS o hosting correspondiente.
Si el tamaño de la landing page o el tamaño total de los archivos JavaScript/CSS supera los 2 MB, nuestros rastreadores no podrán procesarla debido a las limitaciones técnicas de la herramienta.
Para saber más sobre qué puede estar causando el aumento de tamaño de la página y cómo resolver este problema, puedes consultar este artículo de nuestro blog.
Para ver cuánto se ha utilizado de tu presupuesto de rastreo actual, ve a Info de suscripción en tu perfil y busca "Páginas a rastrear" en "Kit de herramientas SEO".
Dependiendo de tu nivel de suscripción, tienes un número determinado de páginas que puedes rastrear al mes (presupuesto mensual de rastreo). Si superas el número de páginas permitidas en tu suscripción, tendrás que comprar límites adicionales o esperar hasta un mes siguiente, cuando se actualizarán tus límites.
Además, si encuentras el mensaje de error "Has alcanzado el límite de campañas ejecutadas simultáneamente" durante la configuración, significa que has llegado al número máximo de auditorías del sitio que se pueden ejecutar al mismo tiempo con tu nivel de suscripción.
Cada nivel de suscripción incluye límites diferentes:
- Cuenta gratuita: 1 auditoría del sitio a la vez
- Kit de herramientas de SEO Pro: Hasta 2 auditorías del sitio simultáneas
- Kit de herramientas de SEO Guru: Hasta 2 auditorías del sitio simultáneas
- Kit de herramientas de SEO Business: Hasta 5 auditorías del sitio simultáneas
Si el dominio no pudo resolverse mediante DNS, probablemente significa que el dominio que introdujiste durante la configuración está desconectado. Normalmente los usuarios tienen este problema cuando introducen un dominio raíz (ejemplo.com) sin darse cuenta de que la versión del dominio raíz de su sitio no existe y que en su lugar habría que introducir la versión WWW de su sitio (www.example.com).
Para evitar este problema, el propietario del sitio web podría añadir una redirección desde el "ejemplo.com" no seguro al "www.ejemplo.com" seguro que existe en el servidor. Este problema también podría ocurrir al revés si el dominio raíz de alguien está protegido, pero su versión WWW no lo está. En tal caso, sólo tendrías que redirigir la versión WWW al dominio raíz.
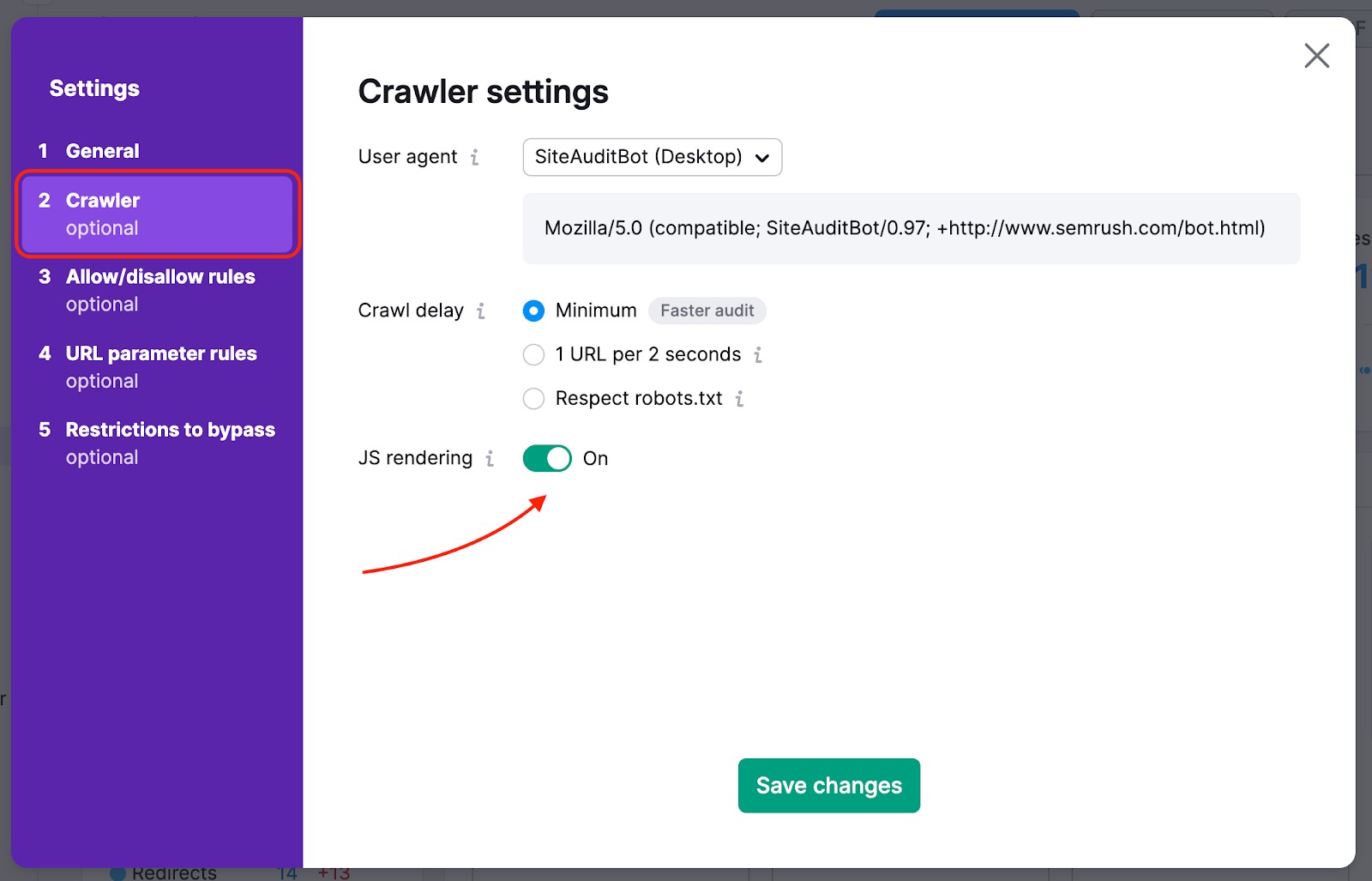
Si tu página de inicio tiene enlaces al resto de tu sitio ocultos en elementos JavaScript, tienes que activar el renderizado JS, para que podamos leerlos y rastrear esas páginas. Esta función está disponible con los niveles de suscripción Guru y Business del kit de herramientas de SEO.
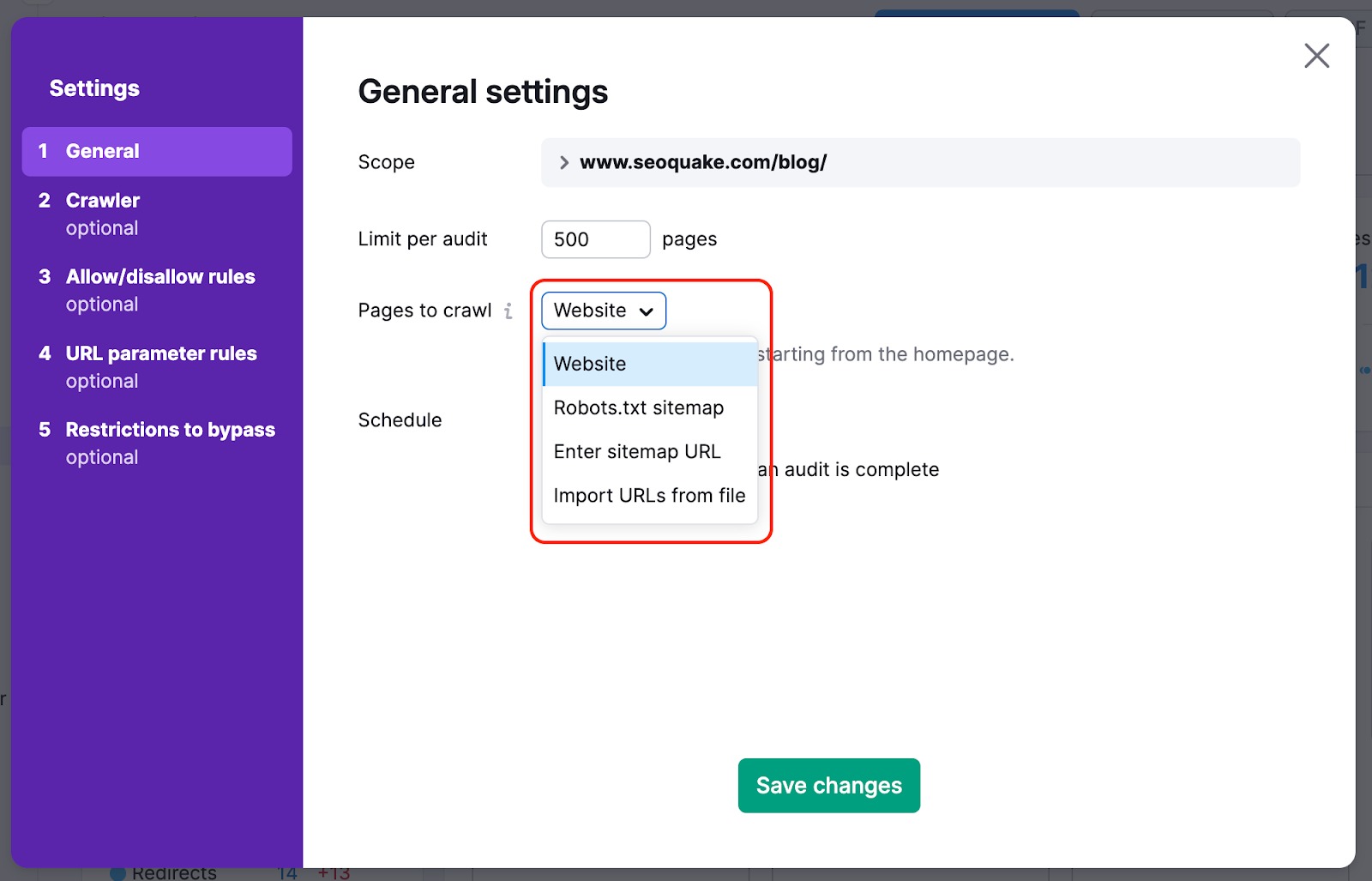
Para no pasar por alto las páginas más importantes de tu sitio web con nuestro rastreo, puedes cambiar la fuente del rastreo de web a sitemap: de esta forma, los rastreadores no se saltarán ninguna página difícil de encontrar en el sitio web de forma natural durante la auditoría.
También podemos rastrear el HTML de una página con algunos elementos JS y revisar los parámetros de tus archivos JS y CSS con nuestras comprobaciones de rendimiento.
Puede que tu sitio web esté bloqueando el SemrushBot en tu archivo robots.txt. Puedes cambiar el Agente de Usuario de SemrushBot a GoogleBot, y es probable que tu sitio web permita el rastreo del Agente de Usuario de Google. Para hacer este cambio, busca la rueda de ajustes en tu Proyecto y selecciona Agente de Usuario.
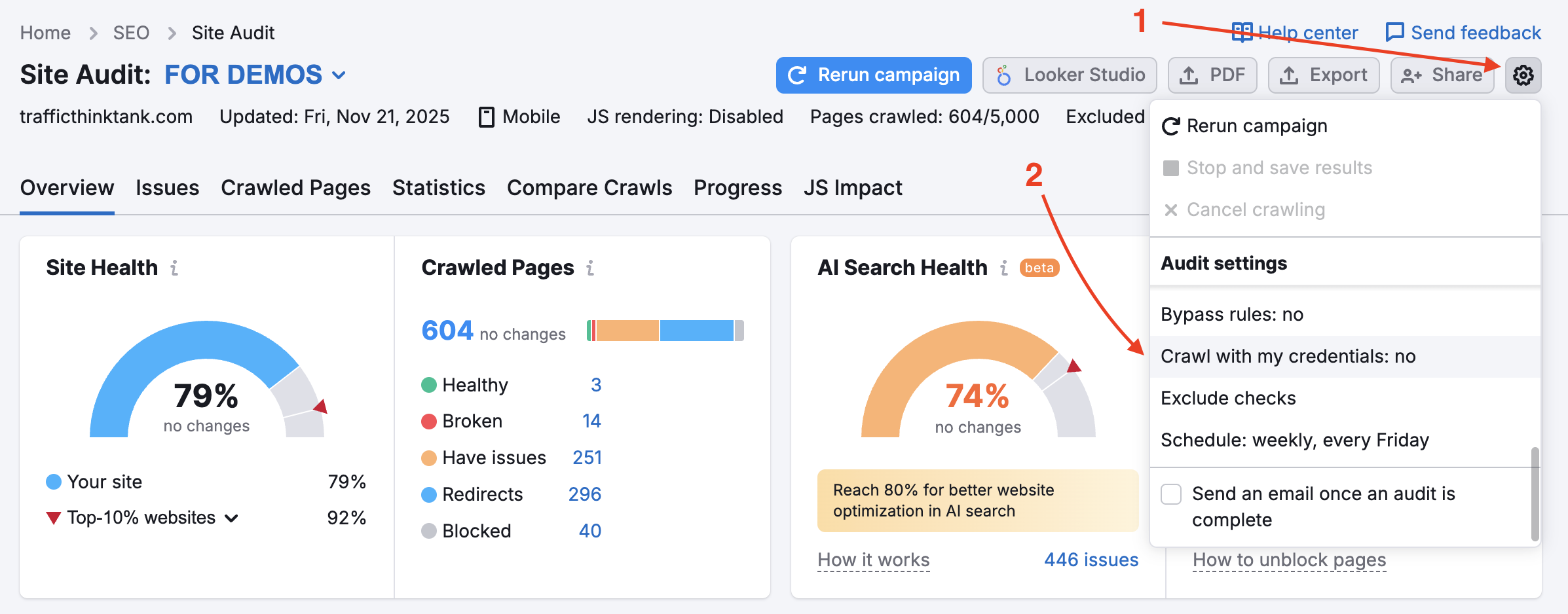
Cuando esta opción está activada, el rastreador ignora las reglas disallow de robots.txt, por lo que se rastrearán páginas y recursos internos que normalmente están bloqueados. Ten en cuenta que, para utilizarlo, habrá que verificar la propiedad del sitio.
Esto es útil para los sitios que están actualmente en mantenimiento. También es útil cuando el propietario del sitio no quiere modificar el archivo robots.txt.
Para auditar áreas privadas de tu sitio web que estén protegidas por contraseña, introduce tus credenciales en la opción "Rastreo con tus credenciales", en el engranaje de configuración.
Esto es muy recomendable para sitios aún en desarrollo o que sean privados y estén totalmente protegidos por contraseña.
Algunos sitios web y plataformas de alojamiento como Shopify pueden bloquear por defecto los bots desconocidos, por razones de seguridad o rendimiento. Si la auditoría falla en estas plataformas, añade una firma Web Bot Auth para que el rastreador de Semrush pueda identificarse como autorizado para acceder a tu web.

Si no proporcionaste una firma durante la configuración inicial y tu sitio web está bloqueado, Semrush detectará la restricción y te indicará cómo arreglarla desde la interfaz de la herramienta.

"La configuración del rastreador ha cambiado desde tu anterior auditoría. Esto podría afectar a los resultados de tu auditoría actual y al número de problemas detectados."
Esta notificación aparece en Auditoría del sitio después de actualizar cualquier opción de configuración y volver a ejecutar la auditoría. Esto no es un indicador de un problema, sino más bien un aviso de que si los resultados del rastreo han cambiado inesperadamente, esta es una razón probable para ello.
Echa un vistazo a la entrada de nuestro blog, Problemas de SEO habituales y cómo solucionarlos.